Запуск локальной нейросети для программирования
Хоть я и стараюсь обычно код писать сам, но в последнее время некоторые рутинные операции (в частности, создание шаблонного кода, документирование и рефакторинг) иногда скармливаю нейросетям. Очень выручал в последнее время AI-агент Qwen Code. Однако, с середины апреля нейросеть Qwen полностью стала платной (исключение составляет пока только официальный web-интерфейс, но это не всегда удобно). Поэтому встал вопрос о локальном запуске нейросетей.
Стал изучать вопрос.
Самыми популярными платформами для локального запуска LLM на данный момент являются Ollama и LM Studio. Вот их и попробуем. А из AI-агентов подключим OpenCode и Qwen Code.
Данные платформы абстрагируют низкоуровневые детали инференса LLM, предоставляя единый интерфейс для загрузки, запуска и взаимодействия с моделями. В основе работы лежит формат GGUF (ранее GGML), который позволяет эффективно квантовать модели и запускать их на потребительском оборудовании, включая CPU и GPU.
| Возможности | Описание |
|---|---|
| Локальный инференс | Все данные обрабатываются на устройстве пользователя, что гарантирует конфиденциальность и отсутствие сетевых задержек |
| Поддержка сотен моделей | Llama 3/3.1/3.2, Mistral, Gemma, Qwen, DeepSeek, Phi, Command R, Neural Chat и др. |
| Аппаратное ускорение | Apple Metal, NVIDIA CUDA, AMD ROCm, CPU (x86/ARM) |
| OpenAI-совместимый API | Позволяет использовать openai SDK, LangChain, LlamaIndex и другие инструменты без изменения кода |
Ollama
Ollama — это бесплатная платформа с открытым исходным кодом, предназначенная для локального запуска, управления и интеграции больших языковых моделей (LLM). Разработана с целью предоставить разработчикам, исследователям и энтузиастам простой способ работы с ИИ-моделями без необходимости настройки сложных ML-стеков или зависимостей от облачных API.
Платформа распространяется под лицензией MIT и активно развивается на GitHub. Поддерживает операционные системы macOS, Linux и Windows.
Примечание:
Ollama автоматически выгружает модели из VRAM/RAM при простое. Повторный запрос перезагружает модель, что может занять несколько секунд.Графический интерфейс
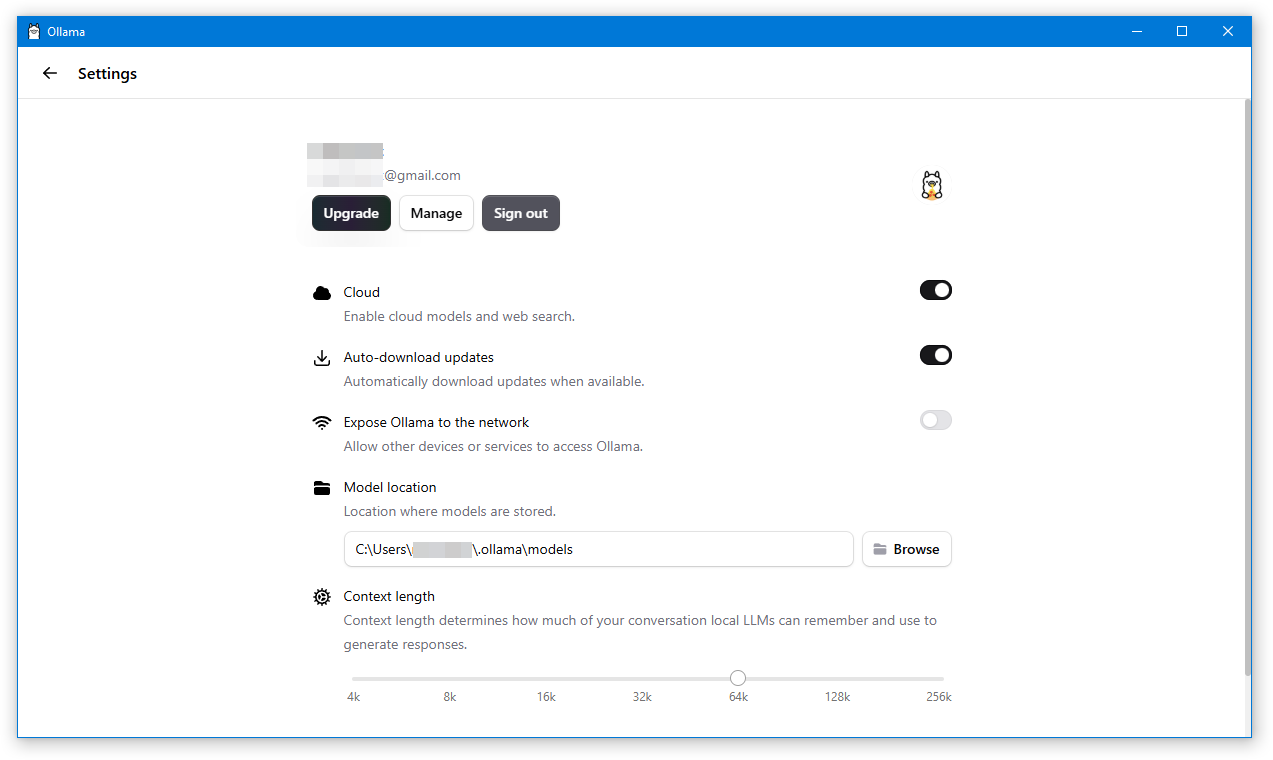
Графический интерфейс Ollama очень простой. Доступен минимум настроек, выбор модели, и собственно сам чат.


Вот собственно и все настройки. Не густо:
Командная строка (CLI)
Управление моделями (их загрузка и удаление) происходит исключительно через командную строку. Их список доступен на официальном сайте.
| Команда | Описание |
|---|---|
| ollama pull <model> | Загрузка модели из реестра (например, llama3.1:8b) |
| ollama run <model> | Запуск интерактивного чата в терминале |
| ollama list | Отображение всех загруженных моделей |
| ollama rm <model> | Удаление модели и освобождение места |
| ollama ps | Список активных (загруженных в память) моделей |
| ollama cp <src> <dst> | Копирование модели для последующей модификации |
| ollama create <name> -f Modelfile | Сборка кастомной модели |
REST API
По умолчанию Ollama запускает локальный REST-сервер на порту 11434, который предоставляет OpenAI-совместимый API, и доступен по адресу http://localhost:11434/v1/
API_KEY можно не указывать, если же он требуется, то можно указать например «ollama» (игнорируется).
LM Studio
LM Studio — кроссплатформенное десктопное приложение с графическим интерфейсом, предназначенное для локального запуска, тестирования и взаимодействия с большими языковыми моделями (LLM). Программа предоставляет удобный способ загрузки моделей из открытых репозиториев, их запуска на собственном оборудовании и интеграции с внешними инструментами через совместимый с OpenAI REST API.
LM Studio был создан командой энтузиастов и разработчиков с целью упростить работу с локальными LLM для пользователей без глубоких технических знаний. Проект активно развивается с 2023 года, регулярно получая обновления, расширяющие поддержку оборудования, форматов моделей и функций взаимодействия. Приложение быстро завоевало популярность среди разработчиков, исследователей ИИ и пользователей, ориентированных на приватность.
LM Studio распространяется бесплатно для личного, образовательного и исследовательского использования. Для коммерческого применения в корпоративных средах или в составе коммерческих продуктов доступна отдельная лицензия. Основная часть интерфейса и клиентских компонентов проприетарна, однако приложение опирается на открытые библиотеки (llama.cpp, GGUF-спецификации и др.), лицензированные под MIT/Apache 2.0.
Графический интерфейс
Графический интерфейс более приятный и функциональный:
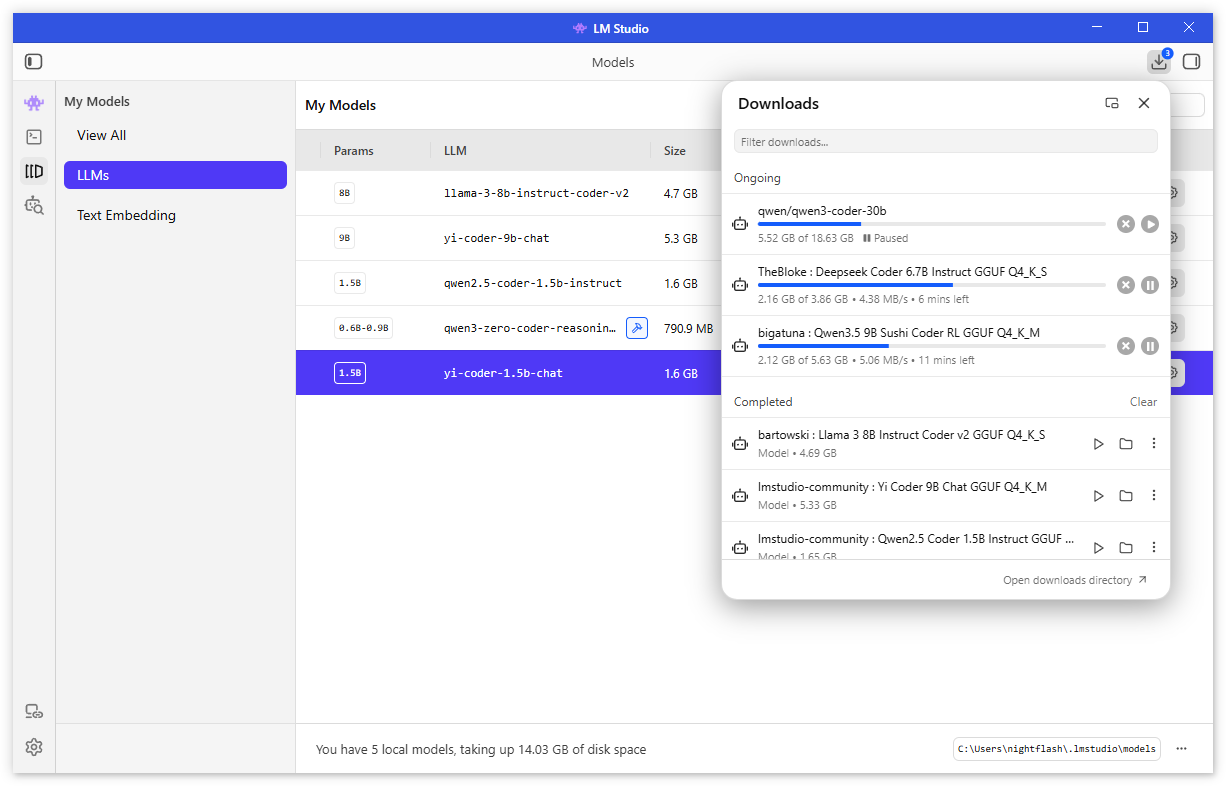
Доступно управление моделями:
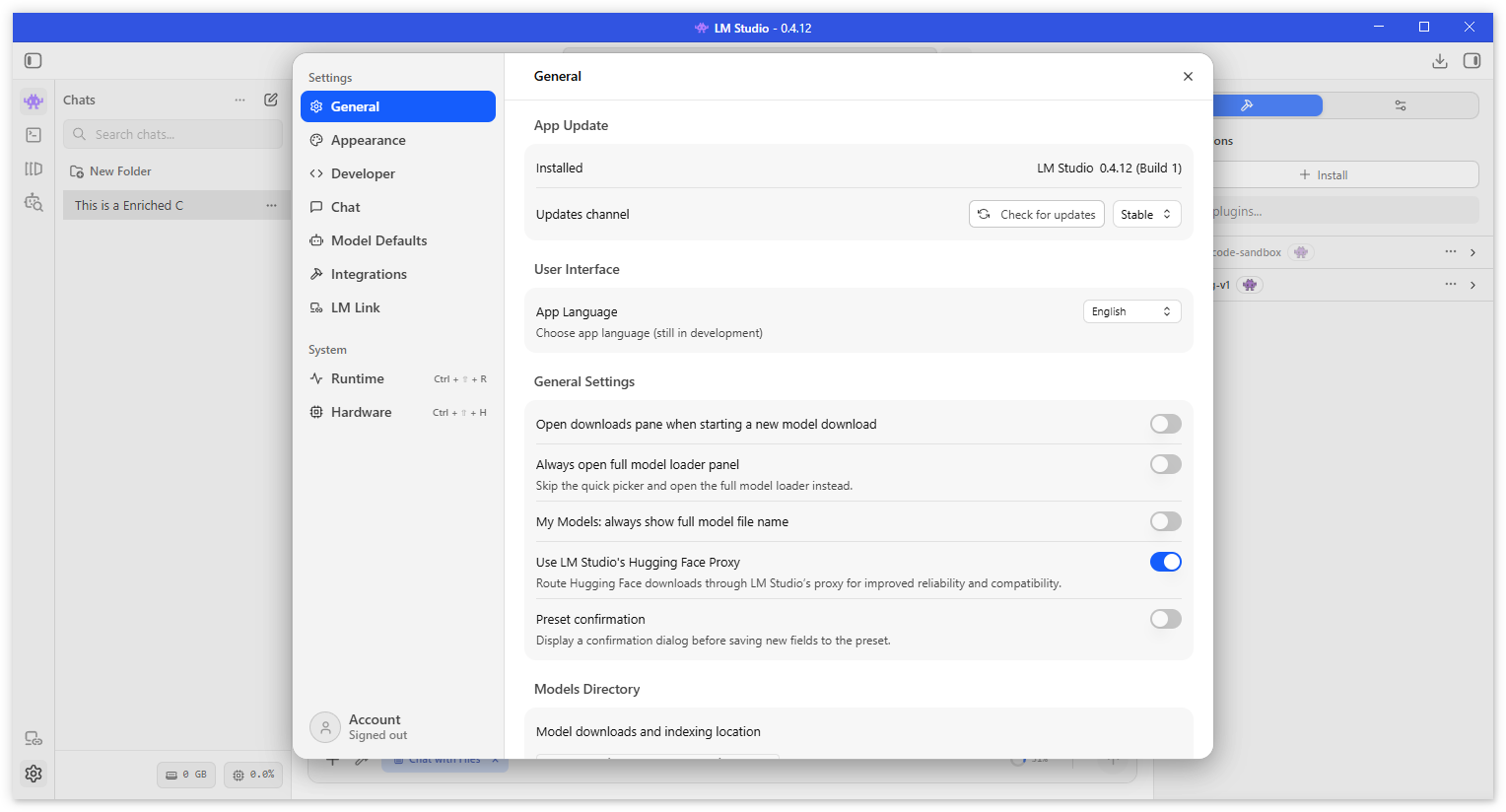
И огромное количество настроек:
В том числе есть подробные настройки для каждой модели при загрузке: длина контекста, загрузка GPU, количество потоков CPU и многое другое:
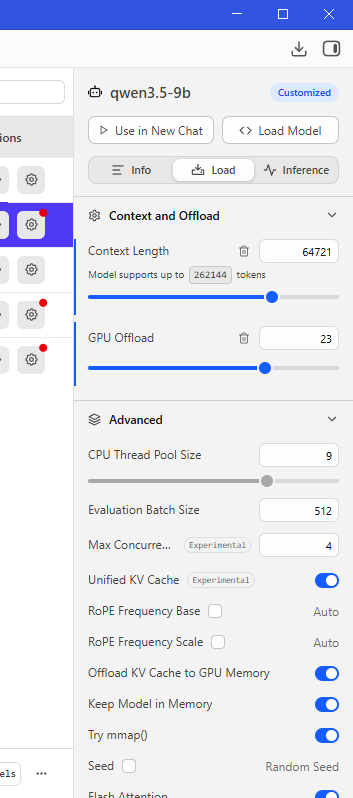
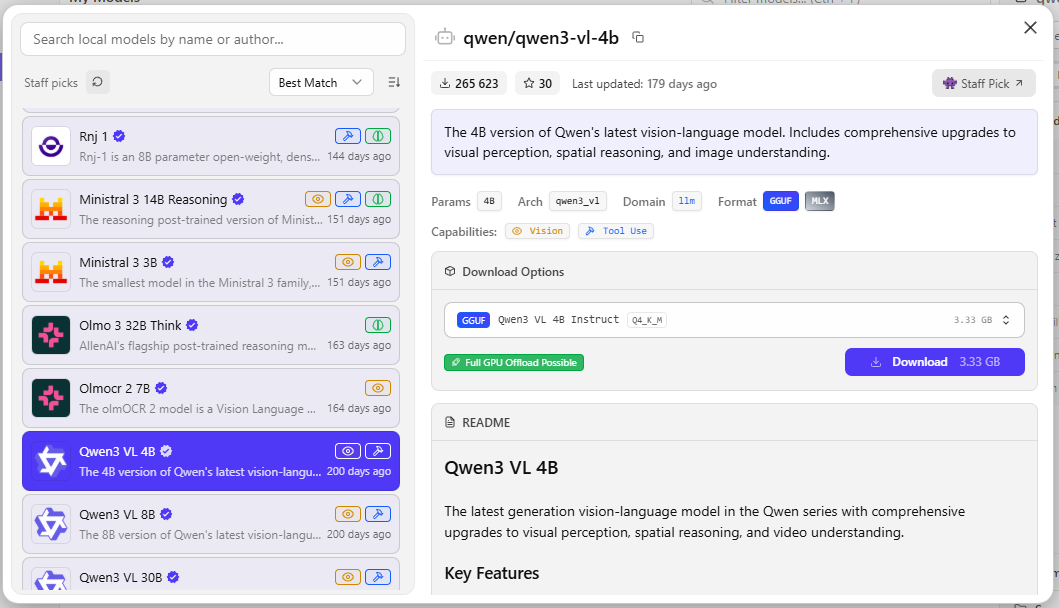
В разделе Model search представлено большое количество моделей для загрузки с подробным описанием. Сразу виден размер загружаемой модели и её параметры. Также имеется метка совместимости с оборудованием:
Full GPU Offload Possible- идеальный вариант. Модель целиком умещается в видеопамяти и будет работать на максимально возможной скорости для вашего железа.Partial GPU Offload Possible- модель частично умещается в видеопамяти, остальная часть будет загружена в оперативную память. Скорость работы будет в разы меньше.Likely too large- модель слишком большая и не поместится в имеющуюся память (VRAM + RAM). Не рекомендуется для использования, так как система будет скидывать излишки в swap, что приведёт к жёстким тормозам. Либо же модель вообще не сможет запуститься.
REST API
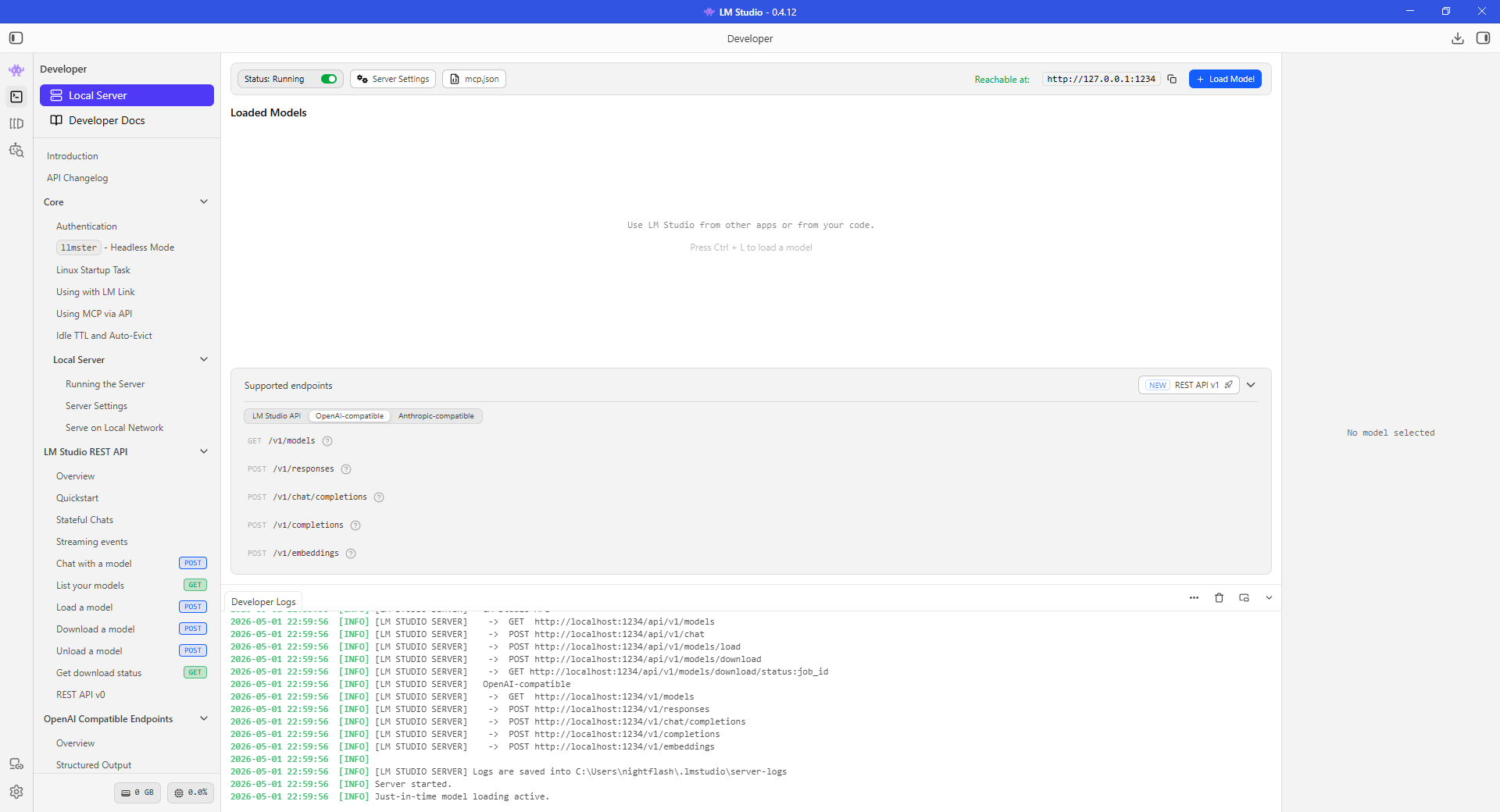
По-умолчанию API-сервер в LM Studio отключен. Для его включения необходимо перейти на вкладку «Developer» - «Local Server»:
И на ней активировать сервер:
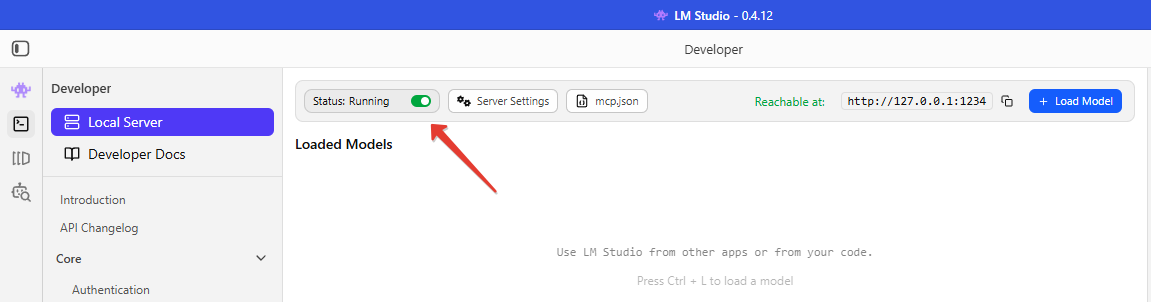
После этого станет доступен OpenAI-совместимый API по адресу http://127.0.0.1:1234/v1.
Затем необходимо создать API-токен. Нажимаем кнопку «Server settings» и затем «Manage tokens»:
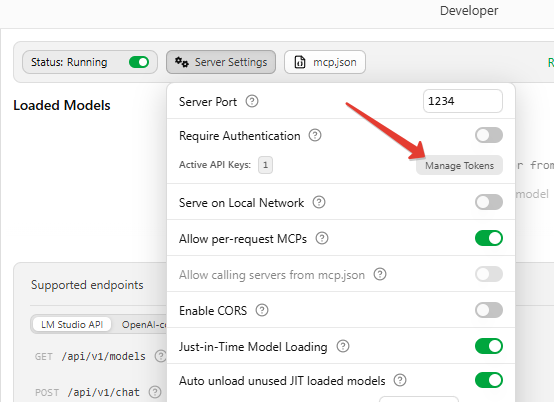
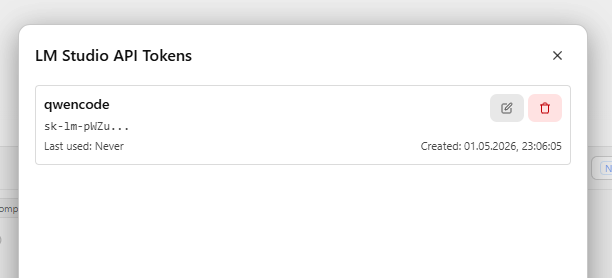
Добавляем новый токен, который обязательно копируем. Он нам пригодится для подключения AI-агента или для использования в своих приложениях на Python.
AI-агенты
Ещё недавно искусственный интеллект в разработке ассоциировался с подсказками в строке или генерацией отдельных функций. Сегодня рынок совершил качественный скачок: AI-агенты получили прямой доступ к файловой системе проекта. Они не просто предлагают фрагменты кода, а самостоятельно создают, переименовывают, перемещают и редактируют файлы, интегрируют зависимости, запускают тесты и фиксируют изменения в системе контроля версий.
AI-агенты, умеющие напрямую работать с файлами кода, — не замена разработчику, а мультипликатор эффективности. Они забирают на себя рутину, ускоряют итерации и снижают порог входа в сложные задачи. Однако их сила пропорциональна качеству контроля: без code review, изоляции и автоматической валидации автономия превращается в риск.
OpenCode
OpenCode — это открытый (open source) AI-агент для программирования, предназначенный для помощи разработчикам в написании, отладке и рефакторинге кода непосредственно в терминале, IDE или десктопном приложении.
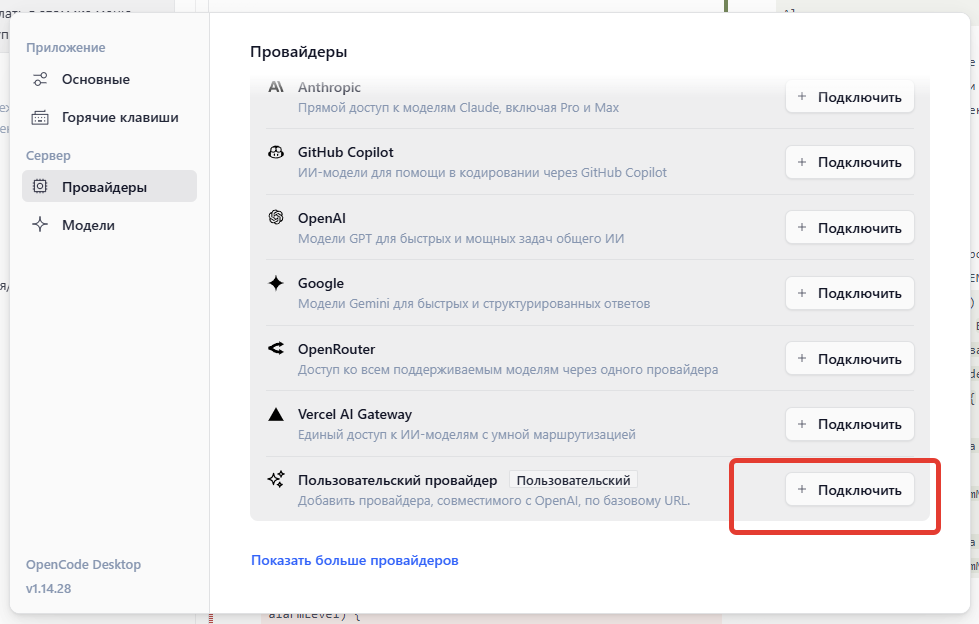
Подключение к провайдеру
Для подключения к провайдеру LLM, в настройках OpenCode выбираем «Провайдеры» и затем подключаем «Пользовательский провайдер»:
| Параметр | Ollama | LM Studio |
|---|---|---|
| ID-провайдера | Указываем любое название из строчных английских букв, цифр, дефиса, подчёркивания. Например, ollama | Указываем любое название из строчных английских букв, цифр, дефиса, подчёркивания. Например, lm-studio |
| Отображаемое имя | То, как вы будете видеть эту модель в списке выбора | То, как вы будете видеть эту модель в списке выбора |
| Базовый URL | http://localhost:11434/v1 | http://localhost:1234/v1 |
| API ключ | пустой, либо ollama | Токен, который создали в настройках сервера LM Studio |
| Модели | указываем необходимую модель, например qwen3.5:397b-cloud | указываем необходимую модель, например qwen/qwen3.6-27b |
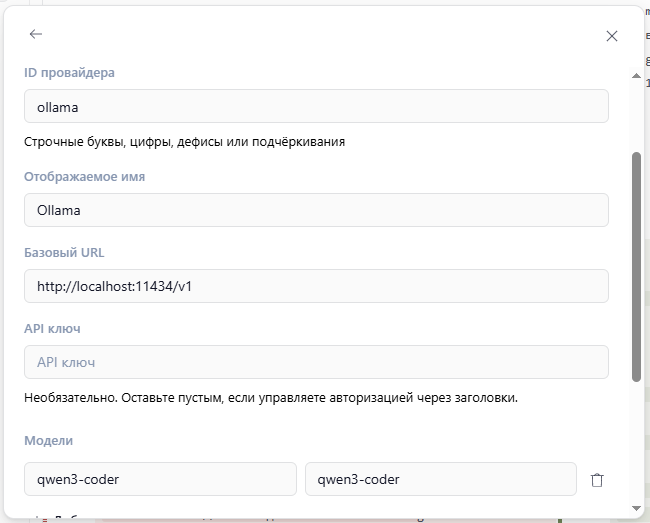
Также можно отредактировать файл конфигурации C:\Users\<username>\.config\opencode\opencode.jsonc . Пример:
{
"$schema": "https://opencode.ai/config.json",
"disabled_providers": [],
"provider": {
"ollama": {
"name": "Ollama",
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"qwen3-coder": {
"name": "qwen3-coder"
}
}
},
"ollama-qwen-cloud": {
"name": "ollama-qwen-cloud",
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"qwen3.5:397b-cloud": {
"name": "qwen3.5:397b-cloud"
}
}
}
},
}
Qwen Code
Qwen Code — это ИИ-агент с открытым исходным кодом для терминала, оптимизированный для моделей серии Qwen. Он помогает анализировать большие кодовые базы, автоматизировать рутинную работу и ускорять разработку. Несмотря на то, что Qwen Code изначально был создан для одноимённой нейросети, к нему очень просто можно подключить и локальные модели.
За счёт того, что это чисто CLI агент, работает он в терминале и соответственно расходует меньше ресурсов, оставляя их нейромоделям. Для его запуска необходимо открыть каталог с проектом (или пустой каталог, если необходимо создать новый проект) и вести команду qwen.
Подключение провайдера
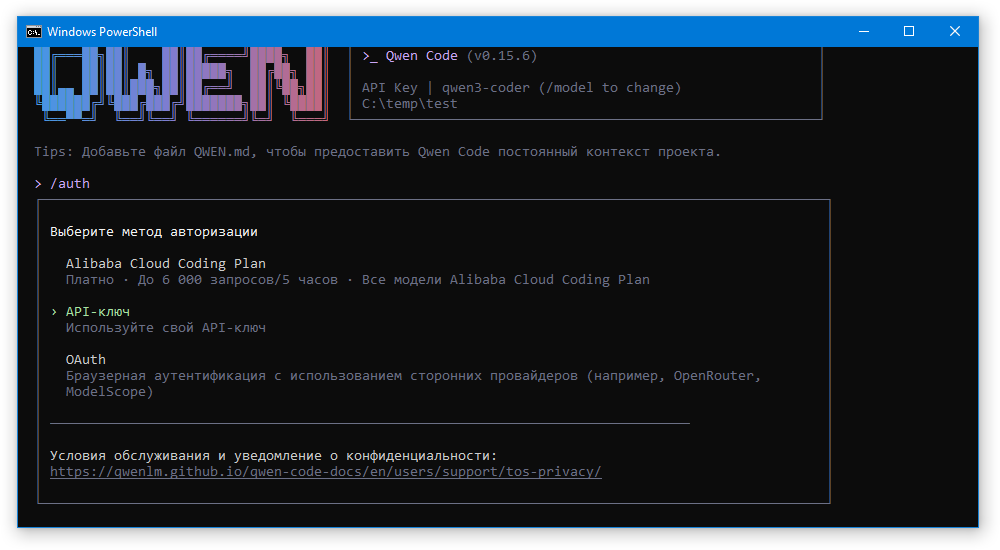
Вводим команду /auth и выбираем пункт API-ключ:
Затем Custom API Key:
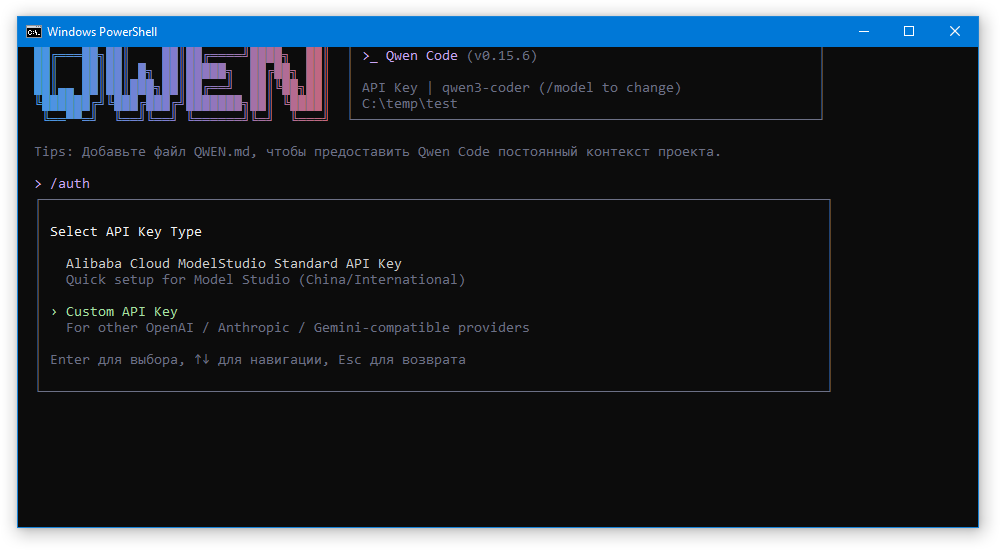
На первом шаге нас спросят протокол. Выбираем OpenAI-compatible:
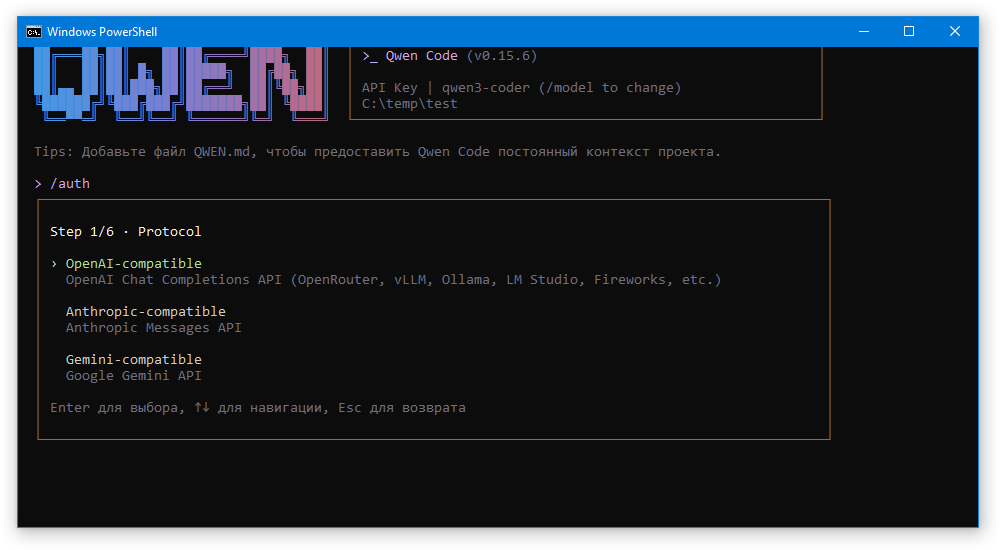
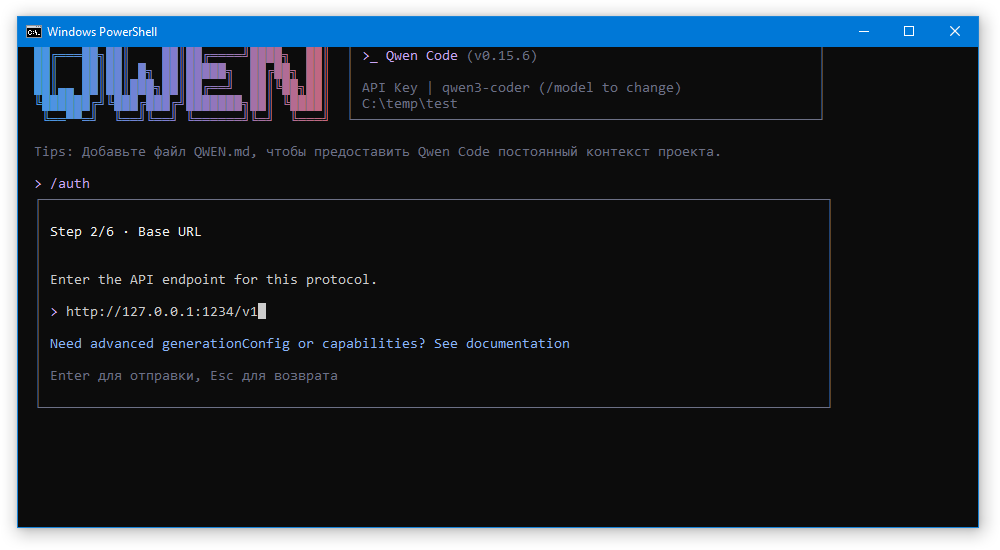
Далее вводим URL к endpoint сервера.
- Ollama -
http://localhost:11434/v1 - LM Studio -
http://localhost:1234/v1
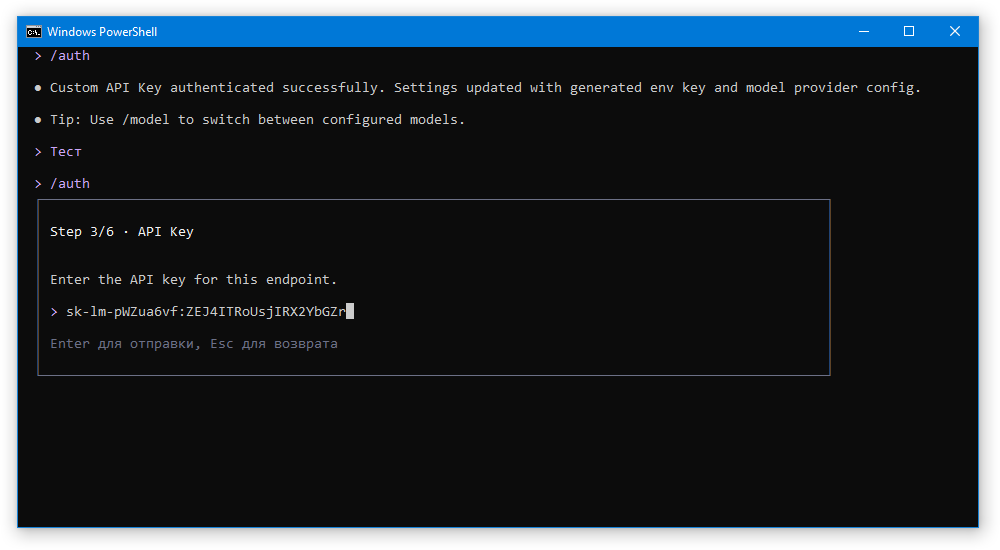
На третьем шаге нас спросят ключ к API. Для Ollama вводим ollama. Для LM Studio вводим токен, который мы создали в настройках сервера.
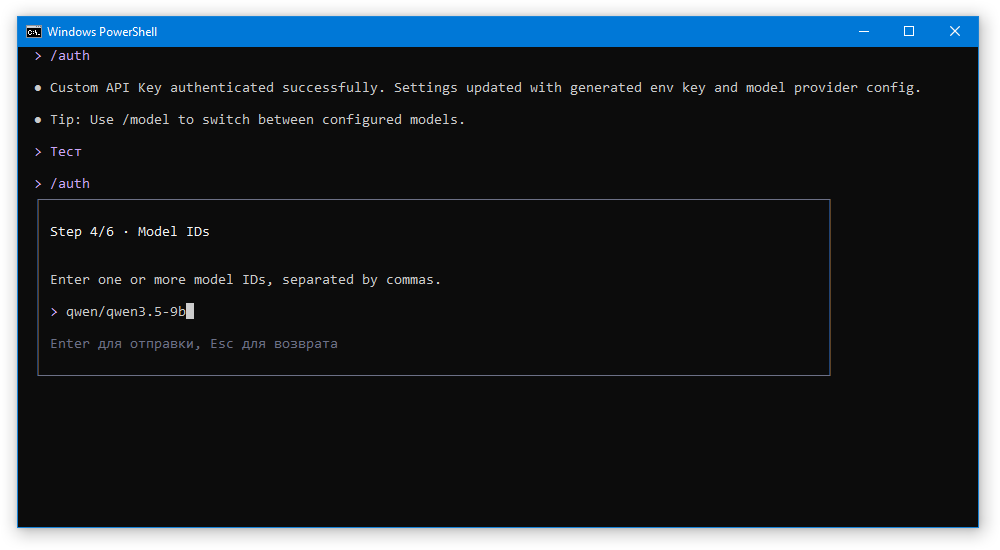
Далее вводим название используемой модели. Как в программе.
Ну и наконец, выбираем, будет ли нейросеть «думать» перед ответом или нет. Это влияет на скорость и точность ответов.
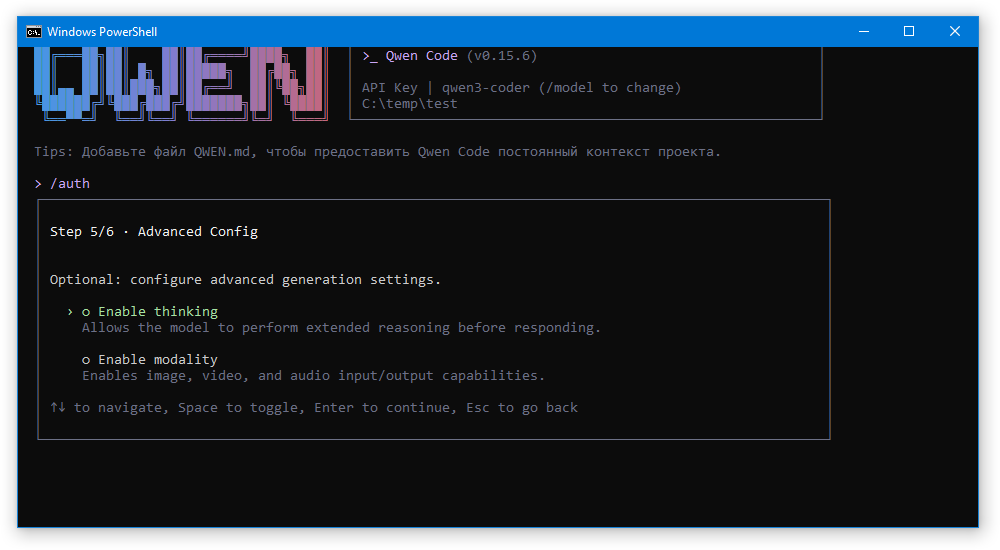
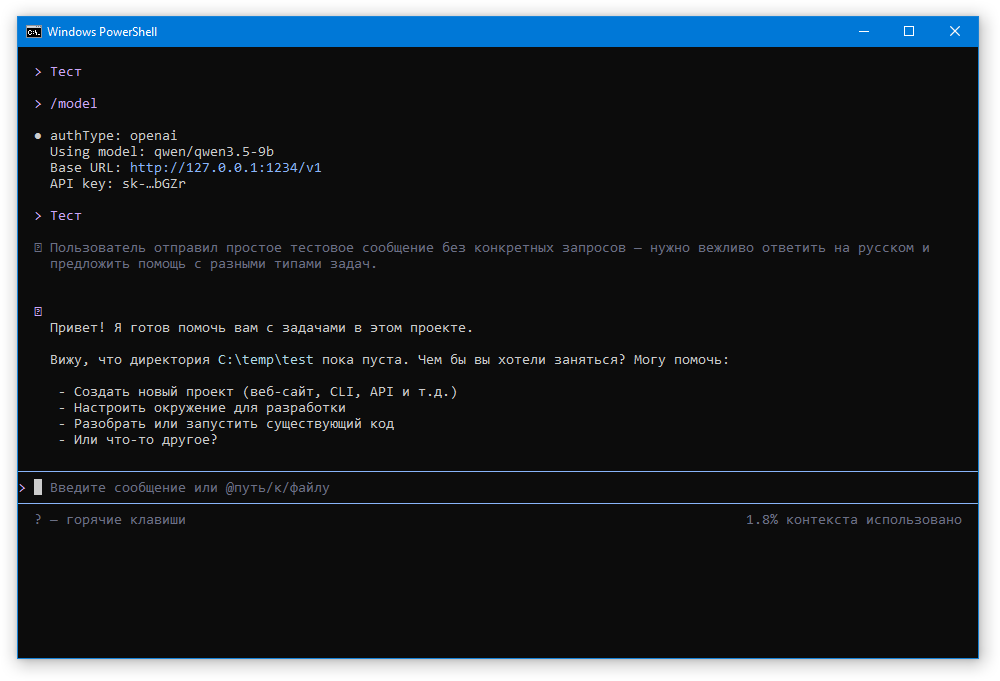
После этого вводим команду /model и выбираем подключенную модель. Теперь AI-агент готов к приёму команд:
Интеграция с Python
Доступна интеграция с Python для взаимодействия с моделями из программы:
from openai import OpenAI client = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama") response = client.chat.completions.create( model="llama3.1", messages=[{"role": "user", "content": "Объясни квантование LLM простыми словами"}], temperature=0.5 ) print(response.choices[0].message.content)